Reading time: 5 min read

Have you ever played Doom? I remember when it came out and one of the main goals was finding the BFG. Well, if you're a Coveo Developer, the Generic Rest API is YOUR BFG for content ingestion. In my opinion.
I'm only going to touch on a few of the basics as, honestly, the capabilities within the Generic Rest API are extensive. And depending on what API you're connecting into, you could spend a good deal of time and effort setting it up.
It is important to understand, this is not a drag and drop, typical configuration. You really need to understand both the API you're connecting to and how Coveo absorbs the information being captured.
Setup A Generic Rest API
After logging into your Admin console, go on and click Add Source.
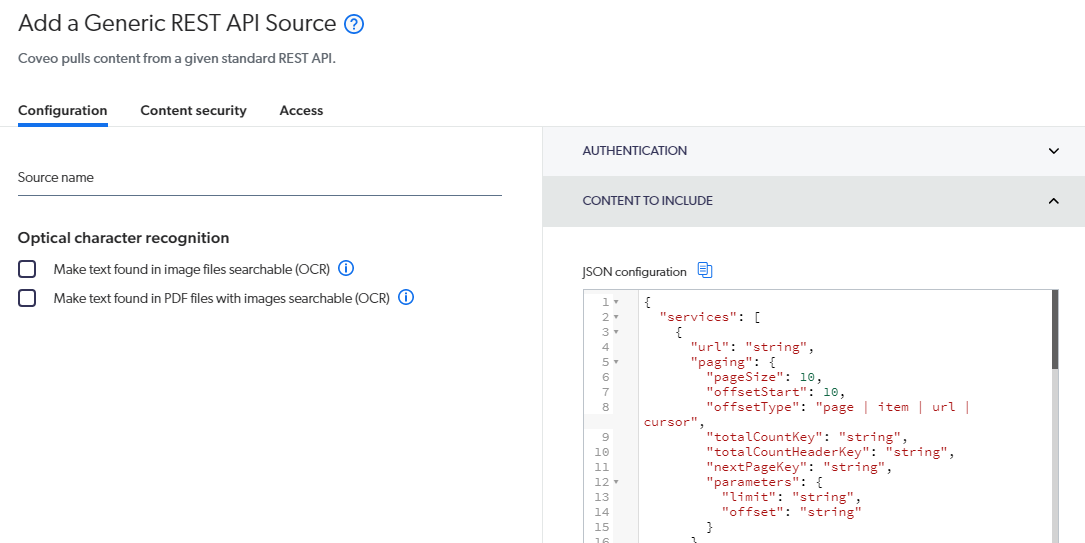
You'll be presented with a typical new source pane. You'll have three areas, Configuration, Content Security and Access. For today we're focusing more on the Configuration piece.
On the right, you have two sections, Authentication and Content To Include.
Authentication
The Authentication tab is broken down further into three main areas.
- Http, Basic, Kerberons, or NTLM authentication(optional)
- OAuth 2.0 authentication (optional)
- API key authentication (optional)
Lots of options, but let's just say you need to have the API key added to the query parameter. Well, by entering it here and then having a corresponding @ApiKey variable used in the JSON configuration below, you can reference it.
Why wouldn't you just put it in the configuration? Well, you could, but if you have more than one admin and varying levels of permissions, that might not be recommended.
Content To Include
Right out of the box, the JSON configuration is enormous and albeit intimidating. Add to the fact there's not much details on what is what. So let's work our way through it all, shall we?
{
"services": [
{
"url": "string",
"paging": {
"pageSize": 10,
"offsetStart": 10,
"offsetType": "page | item | url | cursor",
"totalCountKey": "string",
"totalCountHeaderKey": "string",
"nextPageKey": "string",
"parameters": {
"limit": "string",
"offset": "string"
}
},
"skippableErrorCodes": "string",
"authentication": {
"username": "string",
"password": "string",
"domain": "string",
"forceBasicAuthentication": "true | false"
},
"endpoints": [
{
"path": "string | %[string]",
"method": "GET | POST | PUT",
"headers": {
"key": "value"
},
"queryParameters": {
"key": "value"
},
"paging": {
"key": "value"
},
"itemPath": "string | %[string]",
"itemType": "string | %[string]",
"uri": "string | %[string]",
"clickableUri": "string | %[string]",
"title": "string | %[string]",
"modifiedDate": "string | %[string]",
"body": "content",
"metadata": {
"key": "value"
},
"permissions": {
"permissionsSets": {
"name": "string | %[string]",
"isAnonymousAllowed": "true | false",
"permissionSubQueries": {
"path": "string",
"method": "GET | POST | PUT",
"headers": {
"key": "value"
},
"queryParameters": {
"key": "value"
},
"itemPath": "string | %[string]",
"paging": {
"key": "value"
},
"isAllowedMember": "true | false",
"name": "string | %[string]",
"permissionType": "string | %[string]",
"type": "Group | VirtualGroup | User",
"optional": "true | false",
"condition": "string | %[string]",
"additionalInfo": {
"key": "value"
}
},
"allowedMembers": {
"name": "string | %[string]",
"permissionType": "string | %[string]",
"type": "Group | VirtualGroup | User",
"optional": "true | false",
"condition": "string | %[string]",
"additionalInfo": {
"key": "value"
}
}
}
}
}
]
}
]
}
Holy options batamn. Thing is, you don't need all those. You don't even need a fifth of the options listed above in order to consume a single API call's worth of data.
Learn From Example
We went back to one of our favorite API's, The Movie DB API. You'll remember we used them when we wanted to build a source by Pushing Data Info Coveo.
If we wanted to consume just the first page of an API call's worth of data for the latest, popular movies by using https://api.themoviedb.org/3/movie/popular/?api_key=API_KEY_VALUE, we can create a pull using the following configuration.
{
"Services": [
{
"Url": "https://api.themoviedb.org/3",
"Endpoints": [
{
"Path": "/movie/popular/",
"ItemPath": "results",
"QueryParameters": {
"api_key": "@ApiKey"
},
"Method": "GET",
"ItemType": "Movie",
"Uri": "https://api.themoviedb.org/3/movie/%[id]/",
"ClickableUri": "https://api.themoviedb.org/3/movie/%[id]",
"Metadata": {
"id": "%[id]",
"title": "%[title]"
}
}
]
}
]
}
Remember what we went through to get that same data into Coveo? This is what I'm talking about when it comes to the Generic Rest API.
Subqueries... OH THE POWER!
Typically when you're indexing web pages, each item is a page. Now you can do some fancy stuff by breaking the page up into multiple items. What you can't do is have the lookup go through multiple pages to build a single item. With the Generic Rest API that's EXACTLY what you can do by utilizing Subqueries.
Say in our example above the only way to get both the budget and the revenue on the movie was by doing a subsequent query to an entirely different bath, based upon the data what we are gathering. First thing first is to create both the fields, and the mappings, mdb_budget that will pull in the value found for budget in the corresponding JSON. As well as, mdb_revenue for the corresponding revenue value.
"SubQueries": [
{
"Path": "/movie/%[coveo_parent.id]",
"Method": "GET",
"QueryParameters": {
"api_key": "@ApiKey"
},
"Metadata": {
"mdb_budget": "%[budget]", // Custom mapping, mdb_budget is assigned the value from the budget json attribute
"mdb_revenue": "%[revenue]"
}
}
]
Paging
Most modern API's won't provide you with all the data in a single call. Hence they often use paging. The Movie DB is no different.
"Paging": {
"PageSize": 20,
"OffsetStart": 1,
"OffsetType": "page",
"Parameters": {
"Offset": "page" // This is the name of the query parameter added e.g. &page=10
}
}Our complete configuration would look something like this now. You can see we've also grabbed the movie's overview value and put it under mdb_description.
{
"Services": [
{
"Url": "https://api.themoviedb.org/3",
"Paging": {
"PageSize": 20,
"OffsetStart": 1,
"OffsetType": "page",
"Parameters": {
"Offset": "page"
}
},
"Endpoints": [
{
"Path": "/movie/popular/",
"ItemPath": "results",
"QueryParameters": {
"api_key": "@ApiKey"
},
"Method": "GET",
"ItemType": "Movie",
"Uri": "https://api.themoviedb.org/3/movie/%[id]/",
"ClickableUri": "https://api.themoviedb.org/3/movie/%[id]",
"Metadata": {
"id": "%[id]",
"title": "%[title]",
"mdb_description": "%[overview]"
},
"SubQueries": [
{
"Path": "/movie/%[coveo_parent.id]",
"Method": "GET",
"QueryParameters": {
"api_key": "@ApiKey"
},
"Metadata": {
"mdb_budget": "%[budget]",
"mdb_revenue": "%[revenue]"
}
}
]
}
]
}
]
}
Now with paging enabled along with the subqueries, we've gone from having 20 items in our source to 10,000 very, very, VERY quickly. No need to upload batch data.
